I've been introduced to QlikView lately and it has been somewhat a refreshing experience compared to more traditional BI solution. So this post will give some of the notes taken out of training and after experimentation of the tool.
It turns out I do enjoy it today as a data explorer tool. This allows me to easily navigate through some unknown data model and quickly understand data relationship and hidden rules (not enforced explicitly with defined database constraint). I find this a faster way to explore new data stored in database than going through a lot of SQL request/result analysis iteration.
Here's some additional notes I've gathered:
At 10,000 feet level, there are two major key differentiators :
- The associative nature of the data architecture domain*
- The all in-memory principle
*The associative term is somewhat abusive as it should not be confused with associate data structure (ref). It seems to be rather related to the way front-end dynamically associates data element under selection, and also probably to the automatic association between elements having identical filed name in the data model. It seems that the data is linked using Vector-based association with pointer-type reference.
The underlying data model is actually quite simple: it is built around the familiar concept of datasets with related tables having a number of fields (tabular format). However, there are fundamental rules to respect in regard to that simple model:
- Limit all relation key to a single field (any PK combined fields also used as FK will generate a so-called Synthetic table by QV....which must be avoided)
- Eliminate all circular reference within the whole Data model
- The field key used for relationship between tables must all have identical name (automatic relation generated by QV)
The number of tables can easily reach hundreds while total number of fields reaching thousands. Datasets are always pre-loaded into memory (mandatory) in a compressed format (apparently not using columnar data storage but rather record-based table representation) with very good compression ratio near 10:1**. (from what I could find, the in-memory data is stored through direct compiled machine code ... explaining why only Intel-based processor -multi-core included- are supported as different port would involve intense engineering re-coding and re-optimization).
**As a sidenote: anyone familiar with the de-normalized structure of WH data will not be surprised by this ratio, considering that all data redundancy will be eliminated with the use of pointer in the data structure.
As stated in the 3rd rule, associations are generated automatically against the entire dataset by following this simple convention: all pairs of fields in different table having identical name are automatically part of an association. No particular data model (like star-schema) is assumed, but to remove possible data incoherence/ambiguity, each pair of table must have a single join path (as stated in 2nd rule above). Actually, QV will simply break all redundant links (randomly) to avoid the closed-loop within the data model. This implies that for star-schema model it is practically impossible to traverse multiple fact table within the same QV dataset, except for the rare case where only one common dimension is found between two star-schema...
**As a sidenote: anyone familiar with the de-normalized structure of WH data will not be surprised by this ratio, considering that all data redundancy will be eliminated with the use of pointer in the data structure.
As stated in the 3rd rule, associations are generated automatically against the entire dataset by following this simple convention: all pairs of fields in different table having identical name are automatically part of an association. No particular data model (like star-schema) is assumed, but to remove possible data incoherence/ambiguity, each pair of table must have a single join path (as stated in 2nd rule above). Actually, QV will simply break all redundant links (randomly) to avoid the closed-loop within the data model. This implies that for star-schema model it is practically impossible to traverse multiple fact table within the same QV dataset, except for the rare case where only one common dimension is found between two star-schema...
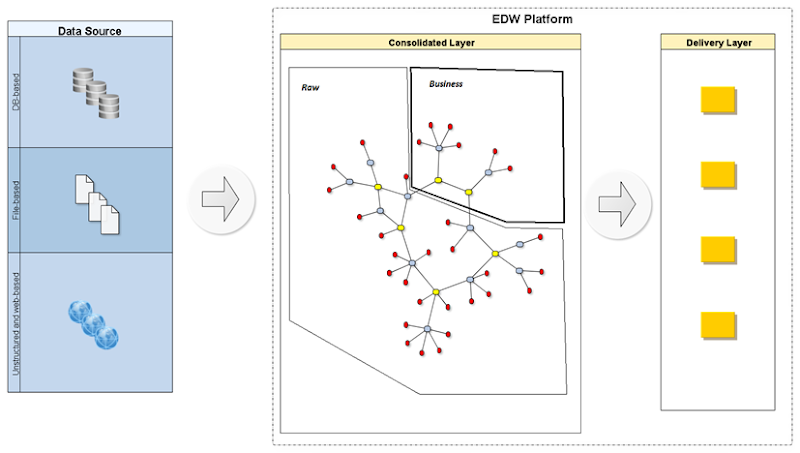
After having configured all your input data and loaded up in QV, you get a data model similar to:
 |
| Figure 1. Example of Data model defined in QlickView. |
All associations are managed at the engine-level and not at the application-level (a typical BI app would need to explicitly manage, store and maintain associations between individual queries association). With QlikView, you always get the associated data as well as the un-associated data elements well highlighted (black and grey-out respectively). That's highlighted by their commercial pitch : QlikView is not a query-based tool! Meaning that data is always linked or associated during analysis instead of having go through iterative query-based analysis in more or less isolated steps:
business question --> query definition --> launch query --> analysis query result -->refine business question --> redefine query definition --> etc...
The data access architecture is not well documented, and it seems to be always fetching data via memory scan, avoiding to have indexes, pre-computed aggregate typically found in other BI-tool in some form or another (see reference The underlying techno..). .
The dataset maximum size that can fit within your host will not be straightforward to calculate as it will depend on the server memory size, compression factor and obviously on other parameters like number of dashboard pages and objects, number of concurrent users connecting to Qlikview server, etc.. Typically, the solution is currently designed for gigabytes-scale databases, but obviously this keeps improving (thanks to Moore's law) especially with the 64-bit server architecture.
business question --> query definition --> launch query --> analysis query result -->refine business question --> redefine query definition --> etc...
The data access architecture is not well documented, and it seems to be always fetching data via memory scan, avoiding to have indexes, pre-computed aggregate typically found in other BI-tool in some form or another (see reference The underlying techno..). .
The dataset maximum size that can fit within your host will not be straightforward to calculate as it will depend on the server memory size, compression factor and obviously on other parameters like number of dashboard pages and objects, number of concurrent users connecting to Qlikview server, etc.. Typically, the solution is currently designed for gigabytes-scale databases, but obviously this keeps improving (thanks to Moore's law) especially with the 64-bit server architecture.
Some drawbacks:
- as always with this sort of tool, you need to extract the data outside your main data repository (whatever that may be) and loaded up inside other server host
- this extract/re-hosting step opens the door to KPI rules duplications/inconsistencies, and uncontrolled data rule transformations that will likely leak outside your central data transfo rules metadata (if you're lucky tro have one)
- scaling and data volume limitations: I came across quite a few Memory error during loading process when dealing with bigger database ... happens especially when loading wider tables (many attributes). The major drawback is that you learn this the hardway...yon only know your database will not fit inside your hardware after spending a considerable amount of time trying to load it into memory!! On some occasions, you actually will need to kill the ‘Not Responding’ app before you can get any response:

Other miscellaneous notes and observations :
- All fields within the data model end-up being an axis of analysis! Even fact-type measure can be queried and searched by.value (more commonly by rinterval of values).
- A file *.QVW is a self-contained QV dataset which potentially include : all data scripting (for data loading into memory), the data itself stored natively in-memory and the presentation stuff (all dashboards and report views)
- Make use of the export native file format QVD, as it offers much better loading performance and good compression compared to the legacy data source.
- we should limit the number of association as it will always be quicker to fetch data within same table. In theory, the complete dataset could fit into a single wide table, however this has some drawbacks like data model understandability.
- Ideally replace Distinct count formula (e.g. Count(distinct EmployeeId)) by adding a simple counter on the table on which we need to count distinct value (distinct involved creating a temporary structure with unique field value on-the-fly).
- Limit the number of tables... so if you have lots of snowflaking inside your WH, try to merge during Data loading into QV.
- When concatenating combined-primary keys into a single field, use Autonumber() [e.g. Autonumber(OrderId & '-' & lineItemNo) ] function to end up with number-based key (instead of String-based key taking more memory)
- All data storage is either : 1- String-based or 2-Number-based (only possible when all values within the table can be interpreted as valid number)
- Number values are read in sequence... i.e. if we have these identical sequence of number: 1.0, 1, 1.000, then only the first value read will be kept (i.e. 1.0)
Martin