Ever heard about Data Vault (DV) Modelling approach? I'll present here some key elements related to the data modelling aspect of this approach invented by Dan Linstedt. For those interested in learning more, you can also check out Dan's freely available educational video.
The modelling technique proposed can leverage one of the advantage going to higher normalization in data warehousing (DWH) schema, i.e. provide more flexibility against data model changes in source. In the era where adapting to changes is our prime requirement in any IT system (if not the only one!), anyone involved in DWH and BI, will clearly see the advantage of this modelling technique when applied to the DWH data integration layer. Not only can you integrate more data from more OLTP's source systems easily, you also can better adapt to data model changes frequently occurring in these OLTPs.
DV modelling is going toward this trend, but we can also see more extreme case where some people suggest the ultimate flexibility with a 6th Normal Form data model (6NF), see Anchor Modelling as a good example of this. Obviously, the price to pay for this flexibility is the explosion of number of tables.... which may be a serious challenge for your EDW, depending on your database engine limitations, data volume, complexity of joins needed to support on-going BI activities, etc.
DV Concepts:
In a very distilled definition, the DV is a simple relational data structure highly normalized and meant to store and preserve "100% of data content 100% of the time" from one or more OLTP data source. The structural modelling has a simple semantic composed of 3 Component (or entity) types: 1- Hub; 2- Link; 3- Satellite.
Key features highlighted by the DV community include:
- “Detail-oriented, historical tracking and uniquely linked set of normalized tables” : hybrid approach in-between pure 3NF and dimensional model to store and preserve all detail and atomic data changes done in operation database
- Flexibility, Scalability and Evolutive to data model changes made possible by separating data structure from data content (more on that below)
- Well suited to near real-time and Massively Parallel Processing (MPP) due to, among any reasons, DML involved are pure Insert (some Update can occur depending on your Satellite implementation choice), and Hubs/Links simplified structure (very narrow row)
- Easy to comprehend and to model: only limited number of entity type and clear semantic associated to each entity type
- Precise and definite normalization applicable for modelling any type of data source while making use of relational concepts
Main proponents argue it is suited to be your integrated layer of the EDW (Enterprise Data warehouse) and thus the main data source for all Star Schema/Datamart and other Delivery Layer components sitting closer to Business. I will not challenge this here as I would need a lot more hands-on experience using DV modelling. So I’ll simply describe the data modelling aspect, which to me, makes perfect sense for your data historical, auditing and trace-ability needs (if not for other needs)!
The meta-model model shown next, depicts each Entity type along with their relationship and characteristics:

1- Hub: one Hub is represented by a single table storing identifiable Entity as found in various functional areas of enterprise data. In other words, these Hubs represent conceptual understanding of your business entities throughout your business line. Examples of these business entities are
- Customer, Subscriber, Product, Account, Party, Order, Call, Invoice, Part, Employee, Purchase order, Service, Inventory, Material, ... (this list getting huge with Corporation acquisition and portfolio growth...)
And example of business lines are
- Sales, Marketing, HR, Finance, Planning, Strategy, Production, Manufacturing, Contracting, etc.
As such these concepts are commonly found and stored in one form or another within all the OLTP systems (i.e. disparate, non-integrated, non-conformed, duplicated..) and we intend to centrally them in our DV repository by first integrate their Keys into Hub.
It must have one or more natural/business keys that allow for unique identification, so Hubs represent the Primary-Keys of our business data, in effect separating structure (Hubs) from the content (Satellite) resulting in better flexibility! Nothing else is stored there, no parent-child relation, no textual info, they must have no other dependencies than themselves. These can then be loaded (near real-time) as "observed" in all OLTP systems without worrying about lookups and relationship constraint.
Typically in Dimensional world, this would be similar to Dimension-keys, but not necessarily as we could also have a Fact table with fact (or transaction) identifiable through natural keys (we would then accompany this particular fact-Hub with a Link structure to capture all many-to-many relationships found in star schema).
Hub Attributes:
- Business key(s) (mandatory) natural composite or single key as used by business people/operational system during operations
- Surrogate Key (*optional according to DV documentation, but surely mandatory especially when used in the context of DWH integrated data). Here the definition of Surrogate key is a bit misleading in all info found, but personally I see three different levels:
- 1. OLTP Surrogate-key provided by source system (most entities cannot be tracked down correctly in time using only business keys, OLTP data models already acknowledged that by using own surrogate-key)
- 2. DV Surrogate-key created by the DV repository: the unique Sequence Id usable as valid PK in the Hub table ( independent and unique across all system source)
- 3. EDW-key (not unique), that would be used to merge and identify same entities across system sources (first level of integration, as suggested in my comments section at end of doc)
- Loading timestamp (mandatory) audit data recording when data was inserted
- Record source (mandatory) the system operational source used for traceability and integration purposes.
2- Link: one Link is represented by a single table storing relationship data between two or more Hub entities (Link could used to connect other Links as well). They represent associations, relationship or links among your Business Entities (contained in Hub). These can change over time, and my or my not have direction (directed from-to).
Instantiated as a separate table, Link can thus support any many-to-many 3NF relationships (i.e. in source system, the relationships between business entity can be of any cardinality types: 1-to-1, n-to-1 or n-to-m) and flexible to support future changes of Cartesian rules. Hence, in source system any FK relationship is a good candidate for Link. The constraint on cardinality types will not be enforced by the database (as all relationship are now modelled as many-.to-many physical structure) but rather the ETL tools, which is typically found on DWH implementation.
Note that Hubs should all have association captured by Links (isn’t it the role of any process to perform some kind of association among business entities), otherwise they would be considered Stand-alone tables and not Hubs (see point 5 below).
Typically in Dimensional world, this would be similar to Fact table. We normally source Link entity from transactional-data in source system, as each transaction is characterized by a few entities, but again, the transaction itself could be represented separately in a Hub. The relevant point is whether the entity is identifiable through business keys, for example transactions could be identified through a unique recognized transaction-Ids ticket.
Link Attributes:
- Hub Surrogate FK Keys (mandatory) Business sequence keys giving the linkage back to each Hub unique Entity (at minimum 2 Entities). These do not correspond to the Hub business natural keys but rather the Surrogate key (can be the OLTP or the DM level key ...depending on the context, but safer to go with the real DM-level surrogate key)
- Link Surrogate Key (*optional according to here) a primary unique key to be considered mandatory in the context of Link connected to other Links, but more importantly, to allow for Context (Satellite) data to relate to Links in a flexible and dynamic way (without being dependent on Links granularity and key changes at source).
- Loading timestamp (mandatory) audit data recording when relationship was first inserted (observed)
- Record source (mandatory) the system operational source used for traceability and integration purposes.
Hubs and Links are free of contextual info, they simply provide structural data. To provide context data, we go to Satellite: the content data.
3- Satellite: one Satellite is represented by a single table storing the contextual, descriptive and information associated to one Hub or Link entity. These are the Content-data of our data model as opposed to Structure-data given by Hub and Link. They must contain some kind of timestamp (an attribute or a numerical sequence pointing to a table that stores these timestamp) used to time frame the observed descriptive data (data valid starting at this given point in time).
They must also contain a unique n-to-1 FK relationship pointing back to the Hub or Link it describes. These will obviously contain a large number of textual fields which are all subject to change over time. As such, Satellites can be defined at grain-level formed by grouping different attributes with similar Rate-of-Change, this will help reducing data redundancy when inserting new rows with updated attributes.
Typically in Dimensional world, this would be similar to type-2 slowly changing Dimension, where we keep track of all state of Fact table.
Satellite Attributes:
- Hub or Link Primary keys (mandatory) FK pointing back to business entity
- Loading timestamp (mandatory) audit data recording when new Textual data was observed and inserted into the table
- Surrogate Key (*optional) a unique key probably useful in the context of m-to-m relationships
- Record source (mandatory) the system operational source used for traceability and integration purposes.
(Optional) 4- Point-in-time: component represented by a single table defined solely to simplify the Querying logic when extracting data from multiple Satellite components (relevant when one Hub entity have many Satellites associated). It is one of possible solution meant to mitigate the issues involved when querying Satellites components :
1) Limited Time Context by row: Inside Satellite table, each record is valid during a limited time span given by the current row and the next row. So to get data content “As-Of” a certain Date, we need to do row-comparison which is cumbersome in SQL (involves sub-select statement to get next row Date).
2) Satellite entity granularity: Textual info data will be buried inside multiple Satellite tables, in effect increasing the number of tables to join and with each involving dedicated sub-select statement to get content As-Of given date.
Point-in-time tables ease the SQL processing burden by combining Load Timestamp related to each Satellite of a business entity into a single structure: PIT-table. Whenever there is a new row inserted from one Satellite, this triggers a new row to be created in the PIT-table, with the Load Timestamp corresponding to the Load Timestamp of the triggering of this particular Sattellite (while keeping timestamp for the other Satellite unchanged). This PIT-table structure is depicted here:
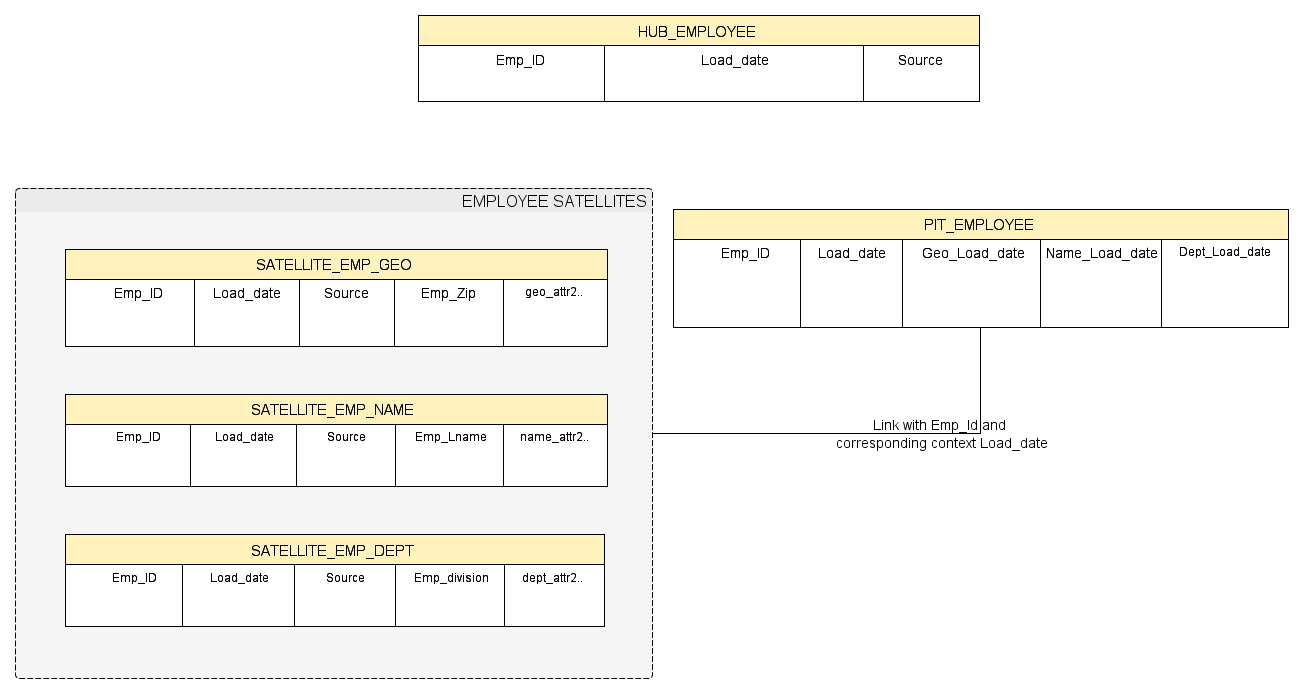
Hence, one wishing to get some Employee name, geo and department info as of “EndOf-lastMonth”, we use the PIT-table to get the right timestamp contextualized by satellite and equi-join with all Satellites needed. This limit to one the number of sub-select statement as illustrated by the pseudo-SQL code below:
| Select pit.emp_id ,geo.geo_attr2 ,name.name_attr2 ,dept.dept_attr2 From PIT_EMPLOYEE pit Inner join SATELLITE_EMP_GEO geo ON (pit.emp_id = geo.emp_id AND pit.geo_load_date = geo.load_date) Inner join SATELLITE_EMP_NAME name ON (pit.emp_id = name.emp_id AND pit.name_load_date = name.load_date) Inner join SATELLITE_EMP_DEPT dept ON (pit.emp_id = dept.emp_id AND pit.dept_load_date = dept.load_date) Where pit.load_date = (Select max(load_date) From PIT_EMPLOYEE p Where pit.emp_id = p.emp_id And p.load_date <= to_date(‘End-Of-lastMonth’)) |
* could also be implemented with more analytical SQL function (windowing LAG/LEAD), but this would still requires a sub-select statement to get the needed row.
Other alternatives could be proposed that avoid the needs to create these artificial PIT table.
We could proceed with a slight denormalization on the Satellites table and add an extra timestamp attribute (Loading_date/Loading_close_date) which is fully redundant with next row timestamp. Then each row would have two timestamp :
- Loading start timestamp (i.e. the mandatory Loading timestamp)
- Loading close timestamp equals to a far-fetched future date when the present record is still valid (current one), or would equal to the next Loading date when that next record came to replace this present one.
| Select geo.geo_attr2 ,name.name_attr2 ,dept.dept_attr2 From SATELLITE_EMP_GEO geo Inner join SATELLITE_EMP_NAME name ON (name.emp_id = geo.emp_id) Inner join SATELLITE_EMP_DEPT dept ON (dept.emp_id = geo.emp_id) Where to_date(‘End-Of-lastMonth’)) Between geo.load_date And geo.load_close_date AND to_date(‘End-Of-lastMonth’)) Between name.load_date And name.load_close_date AND to_date(‘End-Of-lastMonth’)) Between dept.load_date And dept.load_close_date |
So the SQL engine no longer needs to process the sub-query (select max(...) ..) but this come at the price of higher complexity during loading with the required update row to end-date satellite row.
Also possible, is what is referred to by D. Linstedt (original creator of DV modelling) as hybrid or combined approach where PIT table is only used as a way to keep current Load timestamp recorded in all Satellites associated to a specific Hub entity. This new PIT is then refreshed after every load to reflect updated current rows and will contain one load_timestamp field per each satellite table. So new PIT table becomes handy when it’s time to join with previous current row in order to close (end-dating) their status. This approach simplifies Querying only when reporting As-of today data, since PIT only keeps current timestamp There are more issues and difficulties with reporting these data, but this will beyond this introduction doc, please refer to online material.
(Optional) 5- Standalone: component represented by a single table and created to store unrelated Data. By unrelated, we mean data with no real business identity and no business-related linked with existing Hub, such as look-up and other referential data. Examples for Stand-alone tables include calendars, time, code and any other descriptive tables.
My Comments on DV:
Let me first say I believe the data modelling aspect is sound and the approach makes sense for what it is : storing non-integrated relational data in a flexible, dynamic, granular and scalable way from any number of OLTP sources.
However, my concerns are more related to the role that DV data repository presumably could take... i.e. become your established EDW platform (at least one brick of it). This role is promoted by the community and this is where I definitely need more hands-done experience with real implementation done on large Enterprise dataset ecosystem.
If by EDW, we simply mean the staging layer whose role is to consolidate the facts (what and when), and everything else is contained in downstream Datamart layer (i.e. the interpretation of the data) with the application of business rules (i.e. business view), then it is arguably a right fit for this purpose!! But then this discussion comes down to what should constitute your EDW. My view is that it should be more than merely a staging place, so I guess my points below are raised having this concern in mind, but again I hardly saw any real implementation of the DV inside a big EDW environment (may involve a lot more than what is now published by the DV community and made freely available on the net).
◾ Table Explosion: Data structure modelling rules has important impact on the number of tables created, which is significantly more than the corresponding source OLTP databases and obviously more than a corresponding Dimensional model. The explosion in number of tables is due to :
1- cost to pay for splitting Structure from Content (Hubs/Link and Satellites)
2- further splitting content by rate-of-change (many satellites for same entity)
3- modelling any relationship as external m-to-m relationships table
As such, the DV modelling is not rightfully suited to direct reporting/online analysis/ad-hoc querying solution implementation. However, there are techniques modelling that can help circumvent but again at the price of adding more tables. I guess the real solution is to go optimize your Join processing either through sophisticated DB engine or other means.
◾ ODS alternative: If the DV is simply meant to replace your ODS layer, then I’m not sure it makes sense to re-engineer completely this layer to replace with a full DV. First hand, it is not overly complex to build new ODS layer as copy of your OLTP data (plus some timestamp and auditing info) by leveraging ETL tools designed to do full Historical Tracking. So unless, you have stringent requirement for auditing/traceability needs, and that some of your OLTP data models are not suited for building an ODS layer.
◾ OLTP vs EDW Surrogate Key: Obviously adding the OLTP surrogate key in addition to the business/natural keys makes perfect sense, as typically your natural/business keys are not enough to guarantee the correct and unique mapping with same business entity through time, ex. -msisdn changes from time to time (in mobile comm. industry); -ban (billing account #) also may change when client changes account type, employee# can change when same employee move or change status.... So if DV is used as a single source of your EDW downstream layer, yes we need these set of surrogate Keys.
Furthermore, if the goal is to build an Integrated layer of the EDW, then I’d say you also need a deeper level of Surrogate-Key: the EDW-level key! This new key will serve to identify same entity across all OLTP and other source of data in your enterprise. For example, the business entity Employee will have many independent operational systems collecting data all using different set of surrogate/natural keys (ranging from nt-login, employee-No, email-adress, so on...). Adding an EDW-level key will provide you with the first integration hook that ties different entities together (all coming from various OLTP sources).
In this respect, when we load the HUB_EMPLOYEE table, we could simply add this extra-key EDW_EMP_KEY to be used by downstream layer where we combine satellites data (across different OLTP source) for the same business entity element (see next point). And if we work under low latency like in near real-time mode, then to avoid adding concurrent access lock, we could leave these new key as Null, and proceed with special Update in batch-mode during offline window hours.
◾ Can DV be your EDW? When we model the DV as documented, not much integration is provided as we merely provide a central storage where disparate and unrelated-data is accumulated coming from various OLTP sources. At best we would simply be piling up Hub entities from different source (source tag) into the same Hub table, but most likely we would be creating own set of unrelated Hubs, Satellite and Link tables per OLTP source. Although It may be sufficient for your needs, it is not however satisfactory for it to be called your EDW !
◾ Satellites Granularity: the goal of Satellites is to capture (in batch or near real-time) all data changes at source! This can be mandatory for auditing/legal reason, but certainly not for Reporting or data analytical purposes (who cares whether the user proceeding with manual data entry keeps ). So these fine-grained data will impact the EDW by adding extra-rows in the EDW at timeframe scale usually not relevant for most Reporting and BI application needs.
◾ Hub Record deletion : What happen with records are being removed in general? Best practices dictate that business entities normally do not simply disappear from operational database (usually expired or invalidated). But from my experience, in real-life scenario this happens from time to time : who never witnesses a patch executed directly on the operational database with all sort of side effects!. How should we support this deletion:
- Add an optional Deletion_Timestamp in the Hub entity
- Adv. : easily spotted when querying data in Hub without checking Satellite and the appropriate timespan
- DisAdv. : would require row update on the Hub (loading no longer pure insertion logic)
- Add Deletion_flag in Satellite accompanied with the normal Timestamp
- Adv. : leave the loading logic of Hub intact (pure insert)
- DisAdv: Require more complex Satellite query
Either case, this timestamp would only be populated once the record has been “observed” to not exist anymore in the source, having the advantage to preserve traceability. I tend to favor solution I, as explained in the Link Record Deletion below.
◾ Link Record deletion : Also what happen with relationship disappearing (and not simply expired or date-ended from the source)? In other word, what to do with any FK set to Null for a 1-to-m relationship, or a simple deletion of rows in a m-to-m relationship table. As with the Hub record deletion, we could also propose the Link or Satellite approaches as suggested above.
In general, I would not favor the Satellite approach, since Satellites are only meant to carry informational fields existing at the source (content). The Deletion_flag has different semantic and is not sourced directly from existing fields. Record Deletion correspond more to Structural-type than content-type, and as such this info should be carried inside Hub or Link and not Satellites. Furthermore, the semantic to expire/ending an entity or a relationship, is often already built-in explicitly in the OLTP database (i.e. expiration_date, or other flags), which will then be carried over the proper Satellites. So confusion could arise by having these two type of fields in same Satellite.
◾ Direct reporting or ad-hoc analysis: I don’t think DV modelling should be used for direct reporting solution, at least not without the use of some View or technical-layer providing special Query services. This is due to the added complexity (large number of tables, added noise stored in Satellites, more complex join or artificial structure needed to circumvent these, etc..) but as well as due to issues that arise when we simply combine (as opposed to integrate) multiple OLTP data sources. However, DV has a place for the EDW layer focusing on simply storing accurately all data produced by OLTP system without trying to correctly make sense of this data, so in this sense it sort of provides your Staging layer but with full history and completeness. So surely a good solution for data traceability and legal auditing standpoint and possibly some good ideas toward the EDW.
So if chosen as to provide the data collection and historical layer, then I’d say it makes more sense for organizations that have very small investment on their EDW platform, or else organizations that are ready to decommission their current EDW (and here there are probably tons of reasons justifying doing so!). I don’t see cost justification on doing a full revamp/resourcing of current ODS or Integrated layer into Data Vault model.
Martin




