In RPC service layer, I often need special processing to occur before/after some of the call methods. For example, I may want to gather various access statistics related to some of the methods, compress the response when it exceeds some maximum threshold, or yet simply providing a cache response to speed things up!
So in essence, I need to intercept specific RPC calls to provide extra service to these calls and optionally even taking responsibility of handling the call without reaching the real service layer (e.g. as in the case of caching). The logical answer to this need would be to use a AOP solution (Aspect-Oriented Programming), however my service layer are already intercepted by some aspects to manage orthogonal concern such as transactional processing and security handling. And defining additional aspects around my service methods seem counter-intuitive especially for aspects that are relatively sparse (i.e. only apply to a few methods/service).
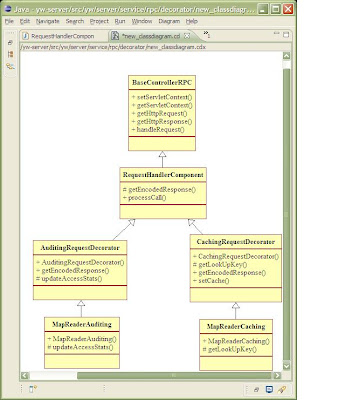
My solution to this problem is simply leveraging the Decorator design pattern. Conceptually, this pattern provides a way to attach additional responsibilities to object dynamically, i.e. here I could add auditing ability or caching ability to the service object. The next UML figure presents the class diagram involved in my solution. It is a slightly modified version of the classic pattern because both my concrete service object (to be wrapped by decorator) and my decorators inherit the same super class. This is more a convenience to centralize the various steps originating from GWT RPC handling mechanism with the template method pattern. The drawback is that all decorators have an annoying dependence on the GWT library. This is fine for my scenario, but I may have to refactor this in order to improving testability.
I’m providing the skeleton source code for the main classes involved, feel free to adapt them to your needs.
(no longer has access to my uploaded file, so I just removed these for now)
Martin
So in essence, I need to intercept specific RPC calls to provide extra service to these calls and optionally even taking responsibility of handling the call without reaching the real service layer (e.g. as in the case of caching). The logical answer to this need would be to use a AOP solution (Aspect-Oriented Programming), however my service layer are already intercepted by some aspects to manage orthogonal concern such as transactional processing and security handling. And defining additional aspects around my service methods seem counter-intuitive especially for aspects that are relatively sparse (i.e. only apply to a few methods/service).
My solution to this problem is simply leveraging the Decorator design pattern. Conceptually, this pattern provides a way to attach additional responsibilities to object dynamically, i.e. here I could add auditing ability or caching ability to the service object. The next UML figure presents the class diagram involved in my solution. It is a slightly modified version of the classic pattern because both my concrete service object (to be wrapped by decorator) and my decorators inherit the same super class. This is more a convenience to centralize the various steps originating from GWT RPC handling mechanism with the template method pattern. The drawback is that all decorators have an annoying dependence on the GWT library. This is fine for my scenario, but I may have to refactor this in order to improving testability.

I’m providing the skeleton source code for the main classes involved, feel free to adapt them to your needs.
(no longer has access to my uploaded file, so I just removed these for now)
Martin












